
Uhlive fournit une suite complète de services pour traiter et analyser la voix (speech analytics, speech-to-text), ainsi qu’une application web pour accéder à ces données. Les fonctionnalités principales sont regroupées en pages : une page d’analyse des conversations sous la forme de tableaux de bord et une page qui affiche la liste des conversations et leurs détails, notamment le transcript caviardé.
Nos clients les utilisent pour rechercher, filtrer et consulter les appels enregistrés (transcriptions, tags et métriques). Pour vous donner une idée de l’échelle, certains clients gèrent des millions d’appels.
L’année dernière, les performances de l’application déclinaient, avec des temps de chargement pouvant atteindre 6 voire 8 secondes. Les utilisateurs nous partageaient leur frustration à travers ce type de commentaires : « C’est un peu long. », « Ça rame. ».
Ce fut un levier puissant et motivant pour consacrer un cycle de développement complet dédié à l’amélioration des performances. Nous avons expérimenté une approche pilotée par les données (« data-driven ») afin d’identifier les problèmes et valider nos avancées par les résultats.
Trouver le problème avec les données terrain (Field Data)
Nous recueillons des données d’utilisation via deux sources principales : New Relic pour les métriques frontend/backend (dont les fameuses Core Web Vitals) et Amplitude pour l’analyse produit.
Celles-ci ont révélé une dure réalité :
- De mauvais scores de LCP : Nos trois pages les plus utilisées étaient les moins performantes, avec un LCP (Largest Contentful Paint) bien au-dessus du seuil « médiocre » de 4 secondes.
- Une corrélation avec le rebond : Notre pire LCP était directement corrélé à nos pires taux de rebond. Les utilisateurs quittaient ces pages malgré des durées de sessions plutôt longues de 4 minutes en moyenne.
- Réactivité : Lorsque la latence d’interaction (INP – Interaction to Next Paint) dépassait 400 ms, le taux de complétion des actions de recherche chutait de 42 %.
Nous avons également examiné l’environnement technique des utilisateurs. Une très large majorité (80 %) utilise un ordinateur de bureau ou portable avec des navigateurs récents basés sur Chrome, sur un système d’exploitation Windows. Mais nous n’avions aucune visibilité sur les capacités réelles de leur matériel (CPU/RAM).
Nous nous sommes donc appuyés sur des signaux indirects. 25 % des sessions se déroulaient sur des écrans inférieurs à 1366px, ce qui est typique d’ordinateurs portables d’entreprises plutôt anciens, conçus pour un travail de bureautique standard. Cette information est importante car le travail demandé par une application Web (scripting, layout, rendu) est moins performant sur ces appareils.
L’amélioration du journal d’appels
Nous avons d’abord concentré nos efforts sur le journal d’appels. Sur six mois, nous avons traversé cinq phases distinctes d’optimisation :
- Optimisation du backend : Optimisations de requêtes et pagination. LCP : −52 % | INP : +202 %
- Nettoyage des requêtes : Suppression du code « mort », réduction du polling. LCP : −22 % | INP : −57 %
- Virtualisation du défilement : Implémentation de TanStack Virtual. LCP : −67 % | INP : −65 %
- Dette liée aux fonctionnalités : Ajout de nouvelles fonctionnalités. LCP : +156 % | INP : −22 %
- Retour à la normale : Migration de points de terminaison (endpoints), réécriture des filtres. LCP : −63 % | INP : +35 %
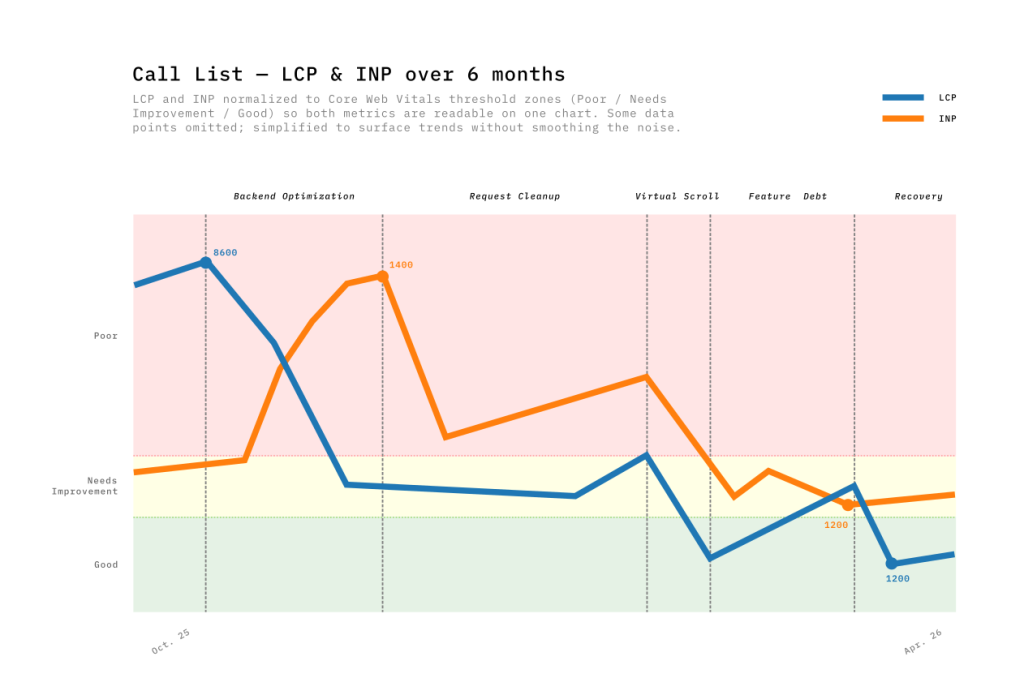 Il serait tentant de tracer une ligne droite passant de 8s à environ 1,5s. Mais comme vous pouvez le voir sur le graphique, la réalité a été beaucoup plus capricieuse — un chemin davantage en forme de montagnes russes.
Il serait tentant de tracer une ligne droite passant de 8s à environ 1,5s. Mais comme vous pouvez le voir sur le graphique, la réalité a été beaucoup plus capricieuse — un chemin davantage en forme de montagnes russes.
Ce que les montagnes russes nous enseignent
Le budget de performance
L’un des enseignements de cette expérience est que la performance se gère comme un budget. Chaque nouvelle fonctionnalité livrée vient consommer, souvent à notre insu, les gains de rapidité acquis précédemment. En effet, les optimisations de performance ne se font pas en vase clos, le développement du produit continue en parallèle.
LCP & INP
Lors de la première phase, quand l’équipe backend a optimisé les appels API, le LCP du journal d’appels est passé de 8600 ms à 4000 ms ! Mais un effet inattendu s’est produit : l’INP a bondi de 420 ms à 1360 ms. Il m’a fallu quelques mois pour comprendre pourquoi, en préparant les données pour cet article… La page se chargeant plus vite, elle livrait plus de données et plus tôt — augmentant le travail demandé au navigateur lors des interactions. Améliorer le LCP pouvait ainsi détériorer l’INP.
Virtualisation
Au cours de la troisième phase, les exigences produit ont évolué : les utilisateurs souhaitaient voir 100 lignes par page au lieu de 20 dans le journal d’appels. Cela a produit un impact négatif sur le LCP et l’INP, en raison du plus grand nombre d’éléments à charger.
La solution standard pour ce type de problème est la virtualisation, une technique astucieuse qui consiste à créer uniquement les éléments visibles à l’écran et non tous les éléments nécessaires à l’affichage des données. Ce gain en performance offre aussi un autre bénéfice pour l’expérience utilisateur (UX) : les utilisateurs perçoivent un temps de réponse homogène, quel que soit le volume des données. La prédiction des temps d’ouverture des pages produit un effet rassurant de stabilité.
Pour l’implémentation, nous avons d’abord utilisé la virtualisation intégrée de PrimeVue, notre bibliothèque de composants d’interface. C’était une solution simple mais nous avons constaté des problèmes d’UX : scintillements lors du défilement, et l’expansion des lignes du tableau — une fonctionnalité centrale pour afficher les résultats de recherches des transcriptions — était chaotique car le virtualiseur ne gérait pas efficacement les hauteurs de lignes dynamiques.
Nous avons trouvé une solution alternative avec TanStack Table. L’approche « headless » de cette bibliothèque signifiait écrire plus de code, mais cela nous a donné un contrôle total sur les éléments du DOM. Désormais, l’expansion des lignes est parfaitement stable et le comportement du défilement est cohérent sur tous les navigateurs. On observe aussi une légère amélioration de la performance par rapport à la première solution. Ce fut le seul moment où le LCP (-67 %) et l’INP (-65 %) ont évolué de concert dans la bonne direction.
Données de laboratoire vs Données terrain
La page des détails d’un appel présente un mode d’utilisation différent de celui du journal d’appels. L’ouverture d’un appel charge :
- La transcription complète (jusqu’à 1h30 de conversation).
- Un lecteur audio synchronisé avec la transcription.
- Les informations et analyses de l’appel : métadonnées, tags et annotations.
Comme la vue en liste, cette page est gourmande en contenu, mais la différence c’est qu’elle est très dynamique : le lecteur audio demande des mises à jour en continu de l’interface pour faire défiler la conversation.
Alors que nos optimisations du journal d’appels sont apparus plutôt clairement dans les métriques réelles des utilisateurs (RUM), la page de détails d’un appel était d’une autre nature. La variation très importante des durées d’appel ont produit des données difficiles à lire et à interpréter.
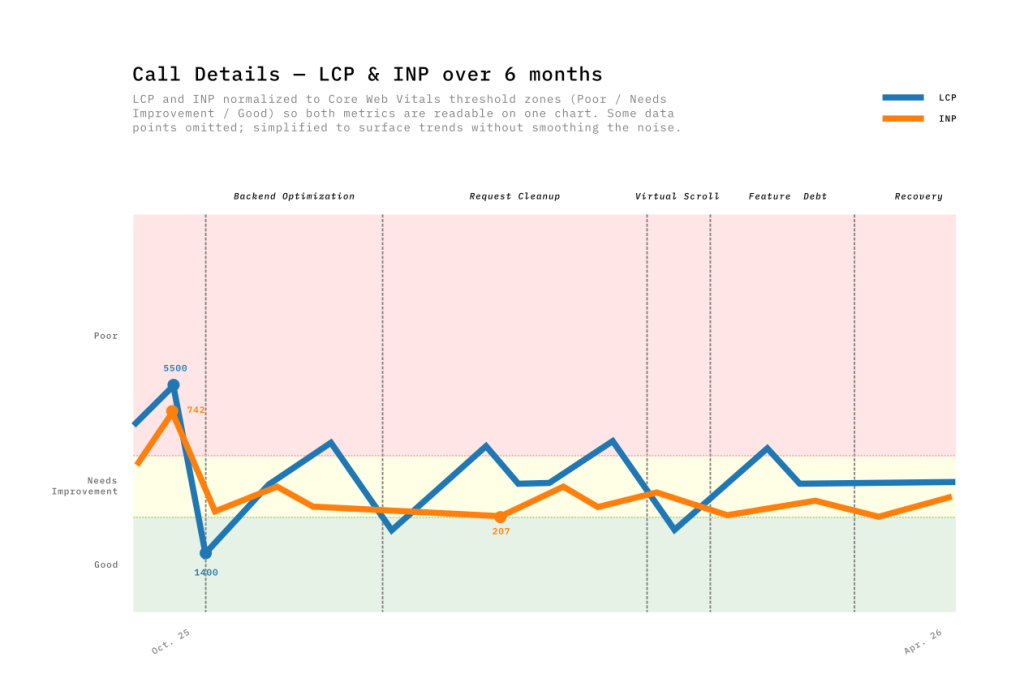 Nous nous sommes donc appuyés sur les données de laboratoire (Lab Data) pour isoler les goulots d’étranglement lors du développement. Avec des scripts Python nous avons analysé les traces de performance et les rapports Lighthouse de Chrome DevTools pour trouver les causes profondes :
Nous nous sommes donc appuyés sur les données de laboratoire (Lab Data) pour isoler les goulots d’étranglement lors du développement. Avec des scripts Python nous avons analysé les traces de performance et les rapports Lighthouse de Chrome DevTools pour trouver les causes profondes :
- Rendu : Nous avons découvert que plus de 7 000 nœuds DOM étaient générés simultanément lors d’un rendu initial. L’implémentation du défilement virtuel a permis de ramener ce chiffre à 30, et ce, de manière constante quelle que soit la volumétrie des données.
- Scripting : Nous avons détecté 20 000 comparaisons par seconde s’effectuant en arrière-plan pendant la lecture de la transcription. Nous avons optimisé la réactivité et la synchronisation du lecteur, en partageant la position active plutôt que les codes temporels bruts (timecode).
- Parallélisation : Nous sommes passés de 5 appels API séquentiels à 3 appels parallèles, réduisant considérablement le temps d’attente initial.
Si ces optimisations sont peu perceptibles sur des machines récentes, elles s’avèrent cruciales sur des appareils plus modestes où l’encombrement du thread principal constitue un goulot d’étranglement. En local, nous avons mesuré un gain moyen de 10 images par seconde (FPS). Cette progression garantit une lecture plus fluide.
Les enjeux de la perception
 En parallèle des changements structurels d’architecture (comme la virtualisation) qui demandent plusieurs semaines, nous nous sommes intéressés à un levier majeur de l’expérience utilisateur : la perception du temps d’attente.
En parallèle des changements structurels d’architecture (comme la virtualisation) qui demandent plusieurs semaines, nous nous sommes intéressés à un levier majeur de l’expérience utilisateur : la perception du temps d’attente.
Nos efforts se sont concentrés sur trois axes :
- Squelettes d’écrans : Un chargement de 3 secondes avec un squelette de mise en page semble plus rapide qu’un chargement de 2 secondes avec un écran blanc — nous avons reproduit la structure finale de la mise en page pour minimiser le décalage visuel lors de l’arrivée des données réelles.
- Interface optimiste : Pour les actions qui ont de fortes chances de réussir, nous mettons à jour l’interface utilisateur immédiatement améliorant la réactivité. La synchronisation avec le serveur se fait en arrière-plan — en ne revenant en arrière qu’en cas d’échec (moins de 1 % des cas).
- Verrouillage d’interaction : Nous avons désactivé les boutons pendant le chargement pour éviter les « clics morts », qui se sont avérés être une source majeure de méfiance des utilisateurs — et avons ajouté des états de chargement explicites (spinners + changements de libellés).
L’impact business
La performance est plus qu’une simple métrique technique ; c’est un argument commercial. En comparant des périodes de 12 semaines avant et après nos optimisations, les résultats ont été indéniables :
- Meilleure efficacité de recherche : Dans le journal d’appels, les utilisateurs consultent 22,6 % de pages en plus par session tout en passant 16,2 % de temps en moins. Ils trouvent ce dont ils ont besoin plus rapidement.
- Réduction des frictions : Le taux de rebond global a chuté de 17,4 %. Moins d’utilisateurs abandonnent l’application par frustration.
- Engagement accru : Sur la page de détails d’un appel, le temps passé par session a augmenté de 11,5 %. Maintenant que la page est exploitable, les analystes s’y installent pour effectuer le travail de fond pour lequel l’outil a été conçu.
Réussir le pilotage : quand les chiffres et les retours s’alignent
Nous avons suivi de près le LCP, l’INP et le TBT, et les améliorations ont été réelles. Mais leur pertinence s’est confirmée lorsqu’elles ont convergé avec la perception des utilisateurs.
Après avoir virtualisé les transcriptions et parallélisé les appels API, un utilisateur l’a résumé ainsi :
« J’ai cru que j’avais changé de matériel. Ouvrir un appel prenait une éternité — maintenant, c’est fait en moins de deux secondes. »
Les tableaux de bord quantifient les progrès ; les retours utilisateurs valident leur impact. Lorsque les deux évoluent dans la même direction, c’est là que l’amélioration devient tangible.
Pour aller plus loin
Largest Contentful Paint (LCP) — web.dev
TanStack Virtual — Documentation officielle
Interaction to Next Paint (INP) — web.dev



