

1. Introduction
1. Context
For years, two 60 TB servers served as the backbone of our storage, replicated over long distances to ensure redundancy. They handled everything from millions of encrypted voice conversations to critical backups. But even the most reliable systems age; eventually, the rigidity of NFS and sync delays couldn’t keep up with our growth. It was time for Uh!ive to move toward a more modern, scalable solution.
2. Objective
AWS S3 storage was already in place for certain services, we naturally opted for a new internal S3 compatible storage.
This solution must be encrypted by default and have the possibility of encryption key rotation. Furthermore, we want a real-time replication system between the different nodes.
2. Phase 1 : Tool Research
Three solutions were evaluated among the various solutions studied:
- Ceph: https://ceph.com/
- OpenIO: https://en.wikipedia.org/wiki/OpenIO
- MinIO: https://min.io/
After basic installations and tests of the solutions, MinIO was finally selected for the following reasons:
- ✅ Very complete documentation
- ✅ Active project on GitHub with 41k stars, 439 contributors at the end of 2023
- ✅ Native encryption via SSE-KMS
- ✅ 100% compatible with the S3 API
- ✅ Prometheus + grafana monitoring
- ✅ Event sending: amqp, webhook, etc …
- ✅ Replication by bucket
- ✅ Possible paid support
- ✅ Complete object retention policy
3. Phase 2 : Target Architecture (staging)
Our tests started on simple VMs, which allowed us to familiarize ourselves with the MinIO configuration, Hashicorp Vault (for encryption), and integration behind our HAProxy.
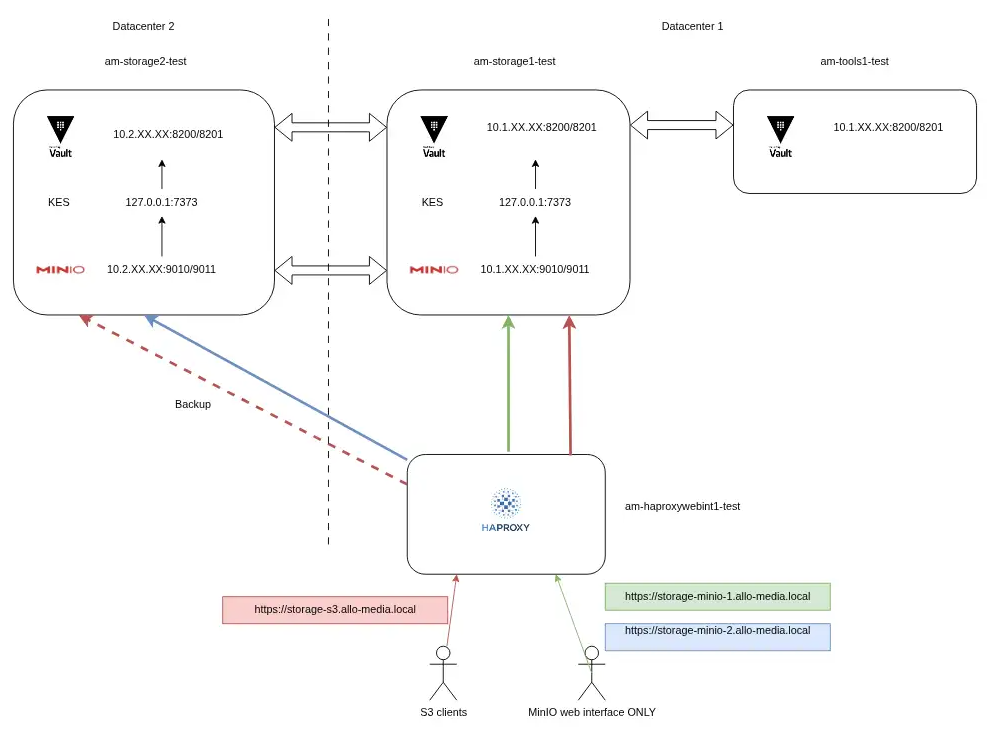
A multitude of tests were carried out on this infrastructure, here is a non-exhaustive list:
- site replication
- versioning data
- retention data
- crash vault 1
- recover after Hardware Failure (drive or server failure)
- HA with HAProxy
We conducted load tests using MinIO’s warp tool. However, since the VM-based staging environment lacked hardware parity with our production setup, the results could not be directly extrapolated. To ensure consistency and reproducibility, all configurations and commands were fully automated and version-controlled via Ansible
4. Phase 3 : Target Architecture (production)
In production, we had 2 NFS servers with 60 TB of HDD storage. So we started again from this same type of server, but with an increased capacity of 8x12TB in HDD.
Capacity calculations were performed with the MinIO calculator: Erasure Code Calculator.
Knowing that the installation and configuration process was already in Ansible, setting up the production infrastructure was very quick.
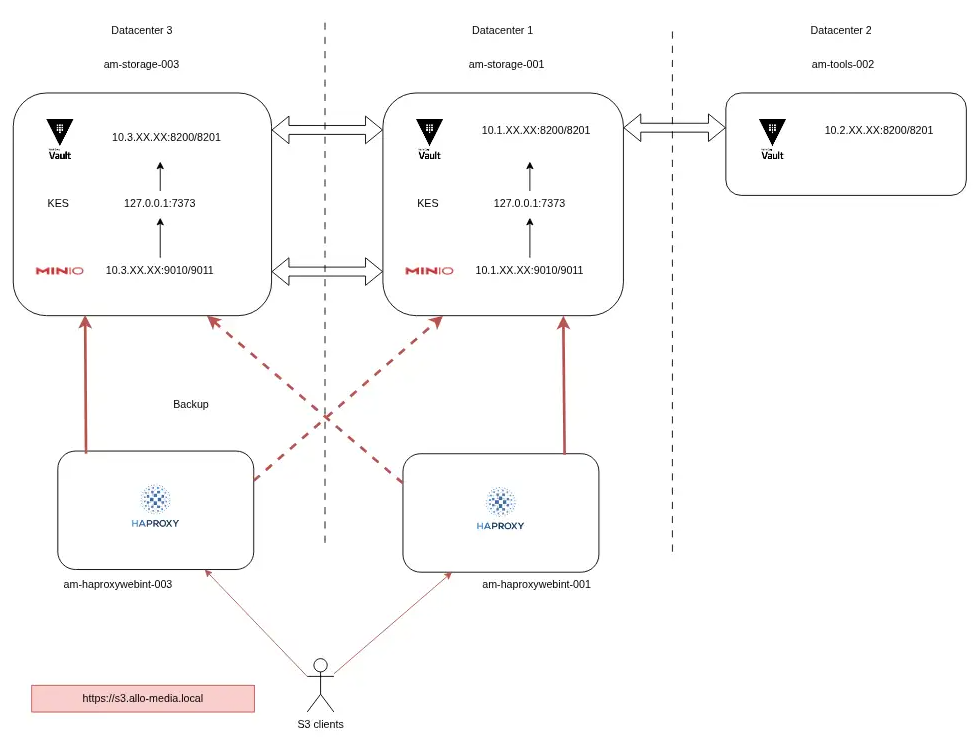 Beyond staging, extensive testing was conducted to ensure the infrastructure was ready for a phased production rollout. We identified a single bottleneck: a slowdown for objects exceeding 10MB, capped at 9 objects per second due to the physical limitations of our 7,200 RPM HDDs. After analysis, we determined this would not impact the initial launch, though we planned for close monitoring as the load on the MinIO servers increased.
Beyond staging, extensive testing was conducted to ensure the infrastructure was ready for a phased production rollout. We identified a single bottleneck: a slowdown for objects exceeding 10MB, capped at 9 objects per second due to the physical limitations of our 7,200 RPM HDDs. After analysis, we determined this would not impact the initial launch, though we planned for close monitoring as the load on the MinIO servers increased.
5. The Performance Problem
At the beginning of the production launch everything worked like a charm, but after some time, we started to show latencies on the availability of audios for batch processing. The impact was low as it concerned batch processing, and none of our real-time pipelines suffered from these latencies.
The problem of slow HDD disks that we had identified during our benchmarks therefore arrived much earlier than initially planned. Indeed, our monitoring reported I/O wait at almost 100% for each of the 8 disks.
Modifications were made to the disk configurations themselves, which allowed an improvement, but still with latencies.
Here is the script based on the MinIO documentation allowing to realize the improvements:
- Deactivation of “retry-on-error” on XFS
- Deactivation of HDD cache
At that time we were not yet at 100% of migrated pipelines, it was impossible to continue this migration and we started the third phase of our project, the implementation of hot / warm.
6. Phase 3 : Hot / warm Architecture
Concept
Tiering is a process that allows working on very fast MinIO servers (“hot” servers), and once all processing on the object is finished, pushing this object to a slower “warm” storage, because only a few readings of the object from time to time will be necessary (“warm” servers).
Moreover, all uploads or readings of objects must be done through the hot servers and all metadata are on the hot servers.
This transfer from hot to warm, takes place every night, thanks to a rule (ILM) which will indicate at what time such or such object must be transferred to the warm.
At Uh!ive
95% of processing on our objects takes place in the first minutes of the pipeline, so we decided to add 2 new hot servers, much smaller than our future warm ones. We opted for servers with 4 TB of NVME, and therefore very fast disk access times, in front of our 60 TB HDD warm servers.
Implementation
As for all projects, we tested tiering and redid all our tests and benchmarks in staging, before starting production.
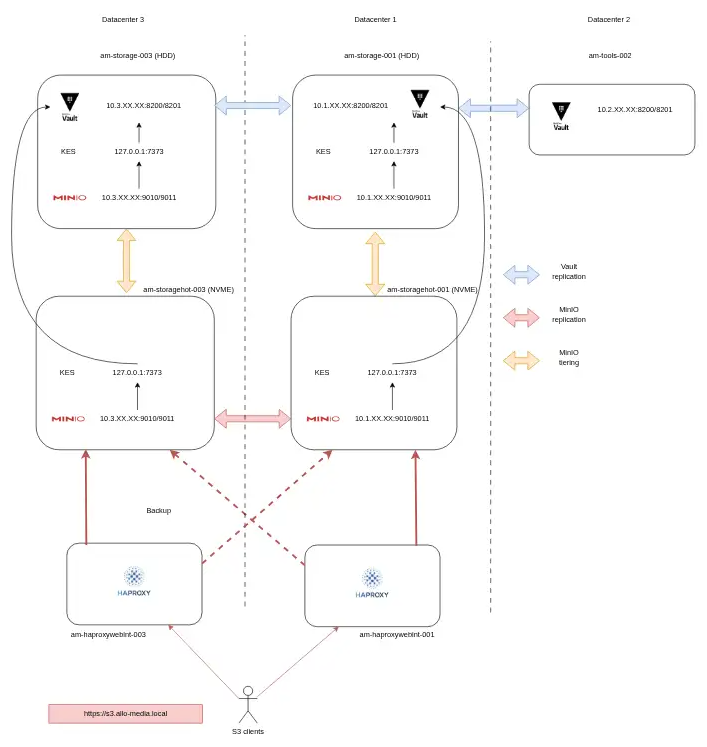 While the staging results were conclusive, we knew they wouldn’t perfectly translate to the production environment. However, following a series of production-level tests, we confirmed that the previous pipeline bottlenecks had been eliminated. With these performance gains verified, we successfully integrated the ‘hot’ servers into our production cluster
While the staging results were conclusive, we knew they wouldn’t perfectly translate to the production environment. However, following a series of production-level tests, we confirmed that the previous pipeline bottlenecks had been eliminated. With these performance gains verified, we successfully integrated the ‘hot’ servers into our production cluster
ILMs
Concerning the ILM (Information Lifecycle Management) rules for tiering, we forced this one to 1 day (the minimum possible, apart from 0, which sends the object immediately to the warm).
As explained previously, our pipelines need many inputs/outputs (PUT, GET) only for a few minutes after their start. So having the object at least 24H on the NVMEs is sufficient to not have slowdowns.
The hot servers were sized to be able to absorb our current traffic for several days in case of loss of the two warm servers.
7. Management of migration to hot / warm
We already had production data on our HDDs, so the metadata was on our warm servers. However, as explained above, the hot has no awareness of objects that have not passed through it because the metadata is always stored in the hot and only the object itself is sent by tiering to the warm.
It was therefore necessary to find a way for our url https://s3.allo-media.local, to be able to both read (GET) old objects that have not passed through the hot, but also write (PUT) and read (GET) new objects which have passed through this new hot / warm system.
The idea was to place an nginx in front of this infrastructure in order to manage intelligent routing between old objects and new ones.
After study, the strongest traffic after migration will be towards the hots. Indeed, upon activation of the hots, the first PUTs and GETs of the new pipelines will be done on them.
Only GETs of current pipelines (which started before the migration) and the few GETs from our UI will have to be redirected to the warms.
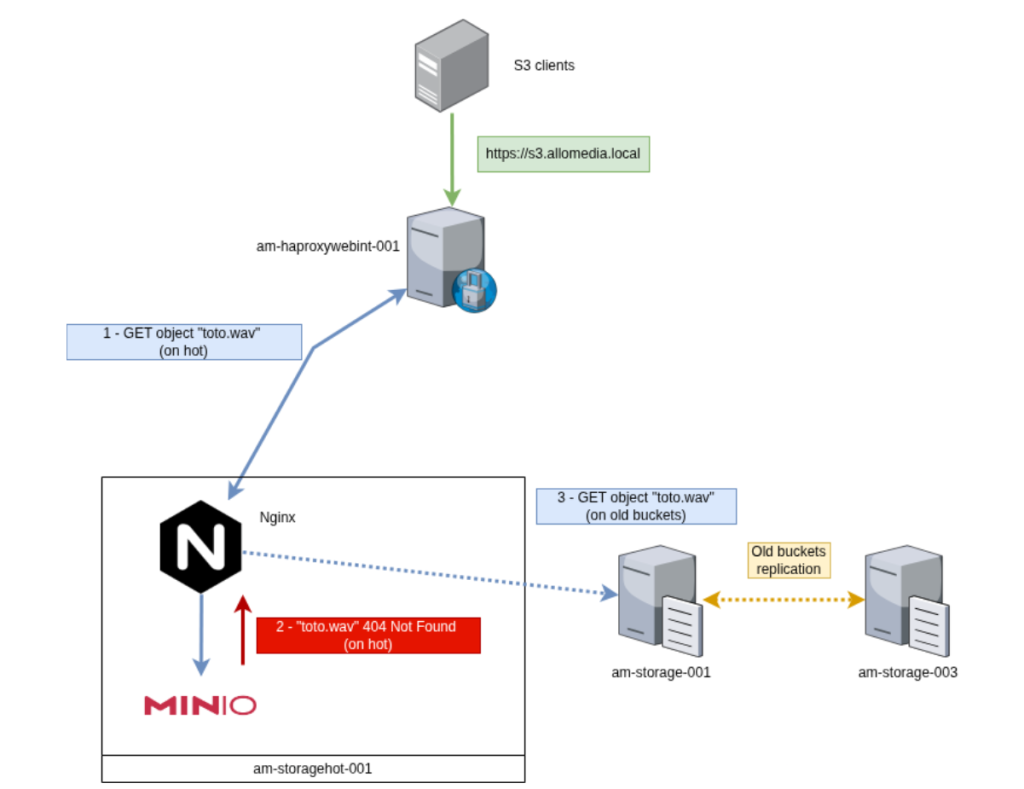
- 1. A request GET, PUT, etc … arrives on our HAProxy
- 2. This request is sent to the Nginx which is hosted on the hot servers
- 3. The nginx will then send these requests to the MinIO hot
- 4. If the requested object does not exist, MinIO hot will return a 404 which will be intercepted by the nginx.
- 5. Nginx will resend this same request to the warm for processing
- 6. If ever this object still does not exist, the warm will return a 404 which, itself, will not be intercepted and returned to the S3 client.
This allows managing the reading of old pre-migration objects, while keeping a single unique URL. So no URL change to plan on S3 clients already migrated. This migration was therefore 100% transparent for our users and no modification or development was necessary to achieve it.
Here is the nginx configuration put in place:
8. Monitoring Management
1. Python daemon for service check
In order to guarantee an effective switchover in case of unavailability of one of the nodes of the MinIO cluster, we have developed a python daemon that will check the integrity of the state of the services. This daemon is used by our HAProxy to perform a check.
At each monitoring request of our HAProxy arriving to this daemon, it will then monitor the 3 services that depend on each other (MinIO, KES, Vault).
If a single one of the three services becomes out of order, the proxies declare the complete node out of order and switch 100% of the traffic to the second.
2. Prometheus + grafana
MinIO is developed with a Prometheus integration, which allows collecting data very regularly. In addition to this, each of our servers linked to the use of MinIO is monitored through the node_exporter tool.
The creation of dashboards with Grafana allows accessibility to data in a structured and personalized way.
The two dashboards provided by MinIO are:
- MinIO Dashboard
- MinIO replication Dashboard
Another personalized dashboard was created to monitor the tiering of objects from hot to warm.
3. Icinga
Icinga is one of the tools used for monitoring at system level. It allows receiving alerts (emails, SMS, chat) in case of technical failure. We carry out classic monitoring (disks, RAM, CPU, daemons, etc …) as well as the state of all services linked to the MinIO infrastructure (MinIO, vault and KES).
9. Conclusion and lessons learned
Thanks to this project, we were able to successfully carry out our modernization towards a true standardized management of files.
Indeed, thanks to this redundancy of files on two datacenters, the strength of MinIO’s native encryption and all that the S3 protocol brings (such as version management), we have “THE” redundant and secure solution responding to our needs.
We learned that despite significant benchmarks and the attempt to reproduce what was happening in production, we could miss certain elements. Even if our latency problems had little impact on production (only a longer availability time of our processing than usual), we never lost data.
The fact of having underestimated the work of the MinIO scanner on millions of small files, also allowed us to deepen the study of this scanner and to adapt it to our needs (between its speed and disk usage (I/O)).
10. Future of MinIO
At the end of 2025 MinIO decided to “freeze” its community version. This was expected, because since 2024 certain signs already showed changes in the community edition, such as the license change, the end of docker images and finally the end of the administration GUI.
We are already starting to study the future of MinIO within our infrastructure, but we think that we still have about a year ahead of us before having to carry out the data migration.
Why a year? Our MinIO infrastructure is 100% internal, never exposed on the internet, so we think that we will not be confronted with big security problems, but if it were the case, we have the skills internally to build a new version with the addition of security patches.