API Speech Recognition


Intégrée à vos outils conversationnels : une reconnaissance vocale optimale, conçue pour faciliter la vie des développeurs.
Word Error Rate
< 5 %
Moteur le plus précis de France, post-LMF
Latence
< 600 ms
Sur flux conversationnels en conditions réelles
Prix
Le + bas
Du marché, avec engagement à la minute
De grandes entreprises, intégrateurs et chercheurs nous font confiance






Language Model Factory
Grâce à notre Language Model Factory (LMF), ne ratez aucun vocabulaire spécifique. Entraînez vos modèles adaptés en seulement 15 minutes et choisissez celui qui convient le mieux à votre cas d’usage.
Un modèle opérationnel en 15 minutes
Jargon, noms propres, acronymes métier
Modèles pré-entraînés par secteur disponibles
01
Modèles sectoriels
Pré-entraînés sur les verticales métier.
02
Jargon et noms propres
Vocabulaire lié à votre activité.
03
Acronymes
Reconnaissance et expansion auto.
04
Expressions métier
Propres à vos processus et cas d’usage.

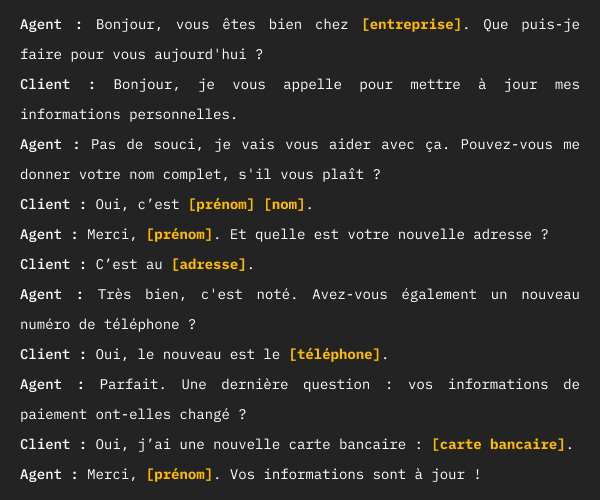
Vocal Cookie
Sécurisation et suppression des données sensibles
Caviardage automatique des informations sensibles en temps réel en fonction de vos cas d’usage : données personnelles, bancaires et de santé.
Transcription sans caviardage / Transcription avec caviardage

Batch
Déposez simplement vos conversations téléphoniques sur FTP sécurisé pour une transcription en quelques minutes, ou en utilisant nos connecteurs :



Langues disponibles
Français, anglais, espagnol, allemand, italien, +5 autres (Europe)
Python SDK
# Dépôt FTP sécurisé import uhlive client = uhlive.connect("api.uh.live") # Transcription batch job = client.transcribe_file( file="appel_2026-04-28.wav", model="fr-telephony-v3", redaction=True ) # Résultat transcript = job.result() print(transcript.text)

Streaming — Live
Connectez directement vos flux audio en WebSocket pour recevoir la transcription en temps réel multi-locuteurs, ou à l’aide de Trunk SIP / SIP REC.
Langues disponibles
Français, anglais, espagnol et allemand
Streaming — Bot
Stream API pour les SVI et Voicebot. Transcrivez vos interactions live avec nos solutions avancées.

Nos protocoles
›MRCP v2
›WebSocket
Built-in pour chaque interaction
Gestion des temps de parole, choix des modèles de langage, grammaires, reconnaissance d’adresses, de dates, de chiffres et de réponses booléennes.
Langues disponibles
Français, anglais, espagnol et allemand
WER < 5 %
Moteur le plus précis en France
100 M
Appels analysés par an
40 %
Des analyses en temps réel
Prêt à transcrire vos premiers appels ?
Accédez à l’API Speech-to-Text uh!ive. Configuration en quelques minutes.
