

1. Introduction
1. Contexte
Historiquement, nous avions deux serveurs de stockage de 60 To chacun, répliqués et hébergés dans deux datacenters différents séparés de plusieurs dizaines de kilomètres.
Ces serveurs étaient configurés pour rendre le service de serveur NFS à l’ensemble de notre infrastructure. Nous y hébergions de nombreuses données chiffrées, comme des millions de conversations audios, des backup de machines, etc…
Après plusieurs années de bons et loyaux services, le manque de synchronisation temps réelle et la rigidité du NFS se faisaient ressentir, et nous avons souhaité moderniser l’ensemble du stockage chez Uh!ive.
2. Objectif
Sachant que du stockage S3 chez AWS était déjà en place pour certains services, nous avons naturellement opté pour un nouveau stockage interne compatible S3.
Cette solution doit être chiffrée par défaut et avoir une possibilité de rotation des clés de chiffrement. De plus, nous souhaitons un système de réplication entre les différents nœuds en temps réel.
2. Phase 1 : Recherche de l’outil
Trois solutions ont été évaluées parmis les diverses solutions étudiées :
- Ceph: https://ceph.com/
- OpenIO: https://en.wikipedia.org/wiki/OpenIO
- MinIO: https://min.io/
Après des installations basiques et des tests des solutions, MinIO a finalement été retenu pour les raisons suivantes :
- ✅ Documentation très complète
- ✅ Projet actif sur GitHub avec 41k d’étoiles, 439 contributeurs fin 2023
- ✅ Chiffrement natif via SSE-KMS
- ✅ 100% compatible avec l’API S3
- ✅ Monitoring prometheus + grafana
- ✅ Envoi d’événements : amqp, webhook, etc …
- ✅ Réplication par bucket
- ✅ Support payant possible
- ✅ Politique de rétention des objets complète
3. Phase 2 : l’architecture cible (staging)
Nos tests ont commencé sur de simples VM, qui nous ont permis de nous familiariser avec la configuration de MinIO, Hashicorp Vault (pour le chiffrement), et l’intégration derrière nos HAProxy.
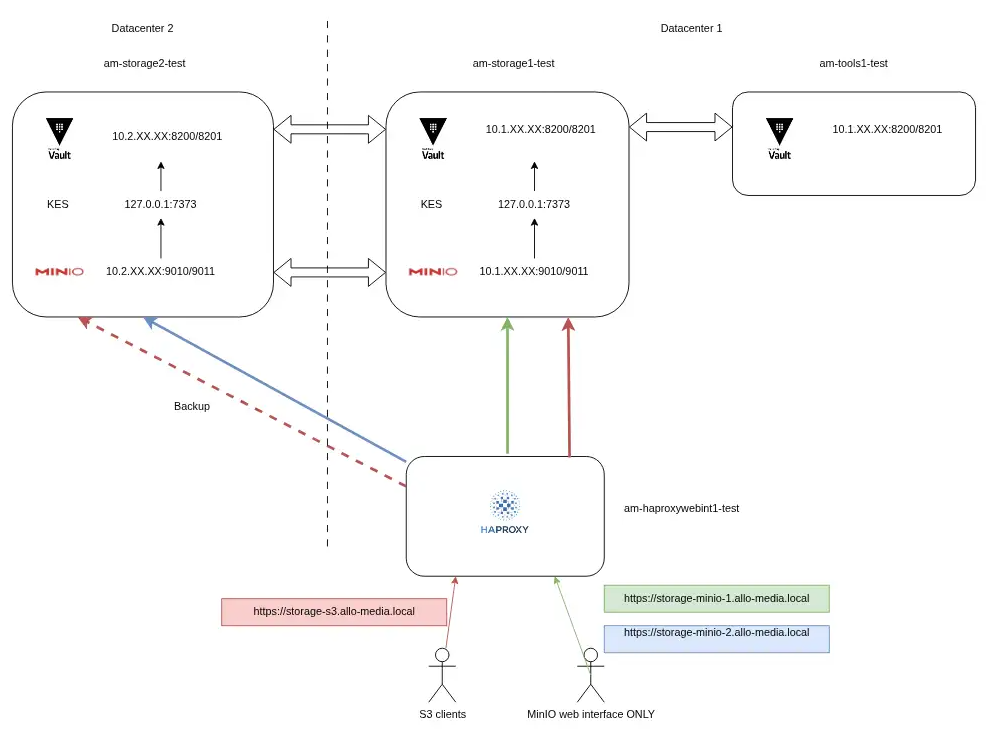
Une multitude de tests ont été réalisés sur cette infrastructure, voici une liste non exhaustive :
- site replication
- versioning data
- retention data
- crash vault 1
- recover after Hardware Failure (drive or server failure)
- HA with HAProxy
Les tests de charge ont été réalisés avec l’outil fourni par MinIO (warp), mais sachant que l’infrastructure de staging (sur VM) ne ressemblerait pas à l’infrastructure de production, les résultats ne pouvaient pas être extrapolés à la production.
L’ensemble des commandes et configurations ont été poussées dans notre orchestrateur de configuration Ansible.
4. Phase 3 : l’architecture cible (production)
En production, nous avions 2 serveurs NFS avec 60 To de stockage HDD. Nous sommes donc repartis de ce même type de serveur, mais avec une capacité augmentée 8x12To en HDD.
Les calculs des capacités ont été effectués avec la calculatrice de MinIO : Erasure Code Calculator.
Sachant que le processus d’installation et de configuration se trouvait déjà dans Ansible, la mise en place de l’infrastructure de production a été très rapide.
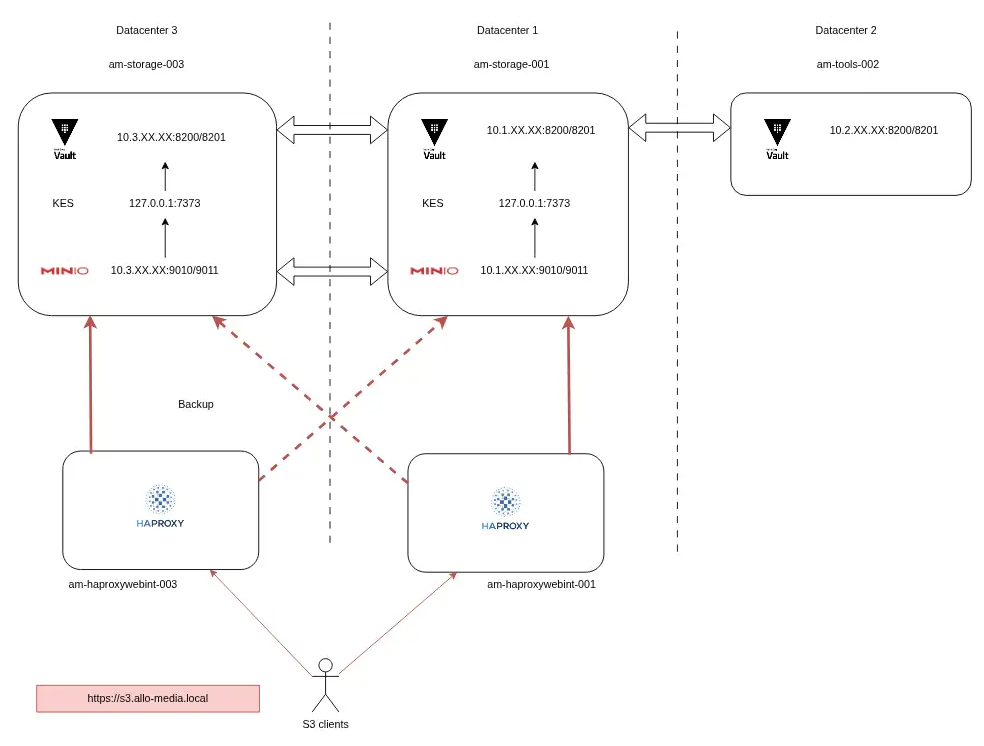
De nombreux tests ont été réalisés en complément de ceux de staging. L’ensemble de l’infrastructure était prête à être mise en production de façon progressive.
A ce stade, seul un problème de lenteurs concernant les fichiers de plus de 10Mo a été identifié (9 objets / secondes, dû aux HDD 7200 rpm). Nous avons étudié la question et jugé que cela ne poserait pas de problème en début de production, tout en prévoyant de rester vigilant lors de la montée en charge des nouveaux serveurs MinIO.
5. Le problème de performance
Au début de la mise en production “Tout marche bien navette”, mais après quelque temps, nous avons commencé à ressentir des latences sur la disponibilité des audios pour les traitements batch. L’impact était faible s’agissant de traitements batch, et aucun de nos pipelines temps réel ne souffrait de ces latences.
Le problème de lenteur des disques HDD que nous avions identifié lors de nos benchmarks est donc arrivé bien plus tôt qu’initialement prévu. En effet, notre monitoring nous remontait des I/O wait à presque 100% pour chacun des 8 disques.
Des modifications ont été apportées aux configurations des disques en eux-mêmes, ce qui a permis une amélioration, mais avec toujours des latences.
Voici le script basé sur la documentation MinIO permettant de réaliser les améliorations :
- Désactivation du “retry-on-error” sur XFS
- Désactivation du cache des HDD
Sachant qu’à ce moment-là nous n’étions pas encore à 100% de pipelines migrés, cela était impossible de continuer cette migration et nous avons entamé la troisième phase de notre projet, la mise en place du hot / warm.
6. Phase 3 : Architecture hot / warm
Concept
Le tiering est un procédé qui permet de travailler sur des serveurs MinIO très rapides (serveurs “hot”), et une fois que l’ensemble des traitements sur l’objet sont terminés, de pousser cet objet vers un stockage “tiède” plus lent, car seules quelques lectures de l’objet de temps en temps seront nécessaires (serveurs “warm”).
De plus l’intégralité des envois ou lectures d’objets doivent se faire au travers des serveurs hot et l’ensemble des metadata se trouvent sur les serveurs hot.
Ce transfert du hot vers warm, se fait chaque nuit, grâce à une règle (ILM) qui va indiquer à quel moment tel ou tel objet doit-être transféré vers le warm.
Chez Uh!ive
Sachant que 95% des traitements sur nos objets se passent dans les premières minutes du pipeline, nous avons décidé de monter 2 nouveaux serveurs hot, bien plus petits que nos futurs warm. Nous avons opté pour des serveurs avec 4 To de NVME, et donc des temps d’accès disque très rapides, qui sont positionnés en frontal de nos serveurs warm de 60 To en HDD.
Mise en place
Comme pour tous les projets, nous avons testé le tiering et refait l’ensemble de nos tests et benchmarks en staging, avant de nous attaquer à la production.
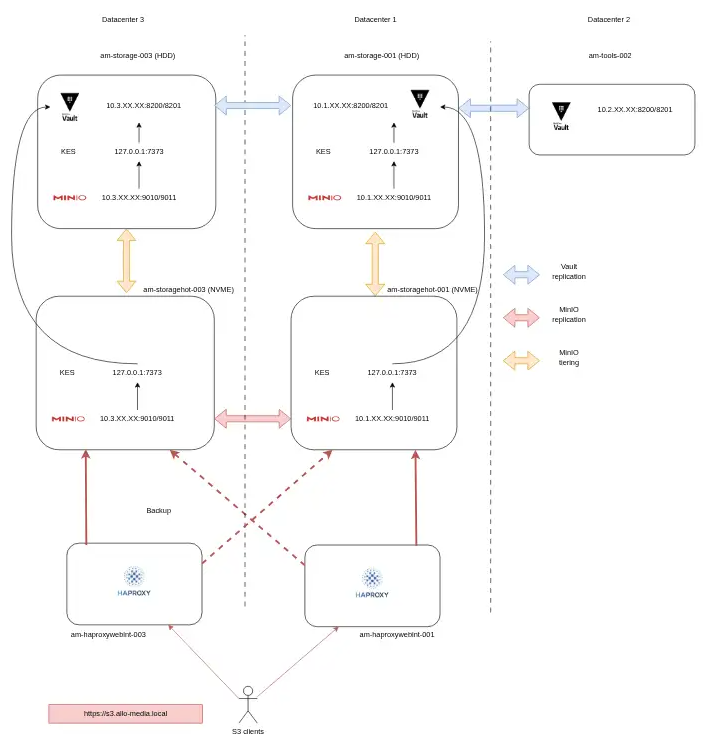
Le résultat a été très net déjà en staging. Mais comme pour la mise en place de la phase 1, nous n’avons pas pu prendre en compte ces benchmarks en staging. Mais des phases de tests ont été réalisées en production et nous avons constaté qu’il n’y avait plus aucun ralentissement sur nos pipelines. Nous avons donc pu ajouter définitivement ces serveurs hot en production.
Les ILM
Concernant les règles ILM (Information Lifecycle Management) pour le tiering, nous avons forcé celui-ci à 1 journée (le minimum possible, hormis 0, qui envoie l’objet immédiatement sur le warm).
Comme expliqué précédemment, nos pipelines ont besoin d’énormément d’entrées/sorties (PUT, GET) seulement pendant quelques minutes après leur démarrage. Donc avoir l’objet a minima 24H sur les NVME est largement suffisant pour ne pas avoir de ralentissement.
Les serveurs hot ont été dimensionnés de façon à pouvoir absorber notre trafic actuel pendant plusieurs jours en cas de perte des deux serveurs warm.
7. Gestion de la migration vers hot / warm
Nous avions déjà des données de production sur nos HDD, les metadata se trouvaient donc sur nos serveurs warm. Or, comme expliqué plus haut, le hot n’a aucune conscience des objets qui ne l’ont pas traversé, car les metadata restent toujours stockées dans le hot et seul l’objet lui-même est envoyé par le tiering vers le warm.
Il a donc fallu trouver un moyen pour que notre url https://s3.allo-media.local, puisse à la fois lire (GET) d’anciens objets qui ne sont pas passés par le hot, mais aussi écrire (PUT) et lire (GET) de nouveaux objets qui sont, eux, passés par ce nouveau système de hot / warm.
L’idée a été de placer un nginx en frontal de cette infrastructure afin de gérer un routage intelligent entre les anciens objets et les nouveaux.
Après étude, le plus fort du trafic après migration sera vers les hots. En effet, dès activation des hots, les premiers PUT et les GET des nouveaux pipelines se feront dessus.
Seuls les GET des pipelines en cours (qui ont commencé avant la migration) et les quelques GET de notre UI devront être redirigés vers les warms.
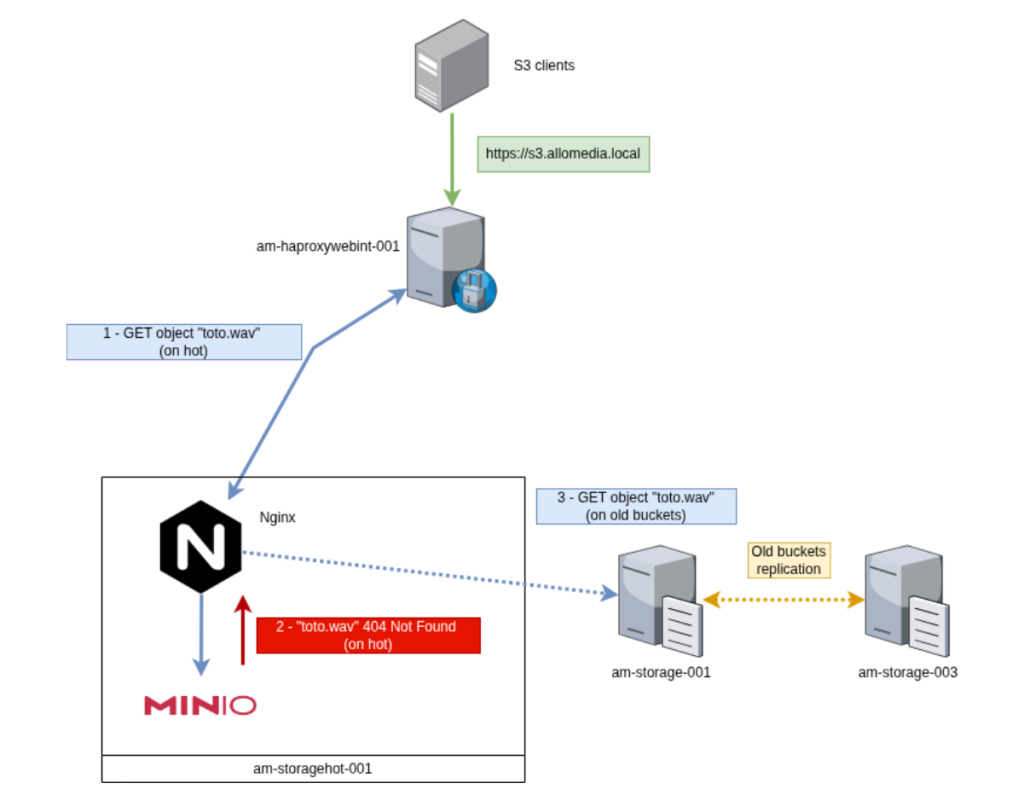
- 1. Une requête GET, PUT, etc …. arrive sur nos HAProxy
- 2. Cette requête est envoyée vers le Nginx qui est hébergé sur les serveurs hot
- 3. Le nginx va ensuite envoyer ces requêtes vers le MinIO hot
- 4. Si l’objet demandé n’existe pas, MinIO hot va renvoyer un 404 qui sera intercepté par le nginx.
- 5. Nginx va renvoyer cette même requête au warm pour traitement
- 6. Si jamais cet objet n’existe toujours pas, le warm renverra un 404 qui, lui, ne sera pas intercepté et renvoyé au client S3.
Cela permet de gérer la lecture des anciens objets pré-migration, tout en conservant une seule et unique URL. Donc aucun changement d’URL à prévoir sur les clients S3 déjà migrés. Cette migration a donc été 100% transparente pour nos utilisateurs et aucune modification ou développement n’a été nécessaire pour la réaliser.
Voici la configuration nginx mise en place :
8. Gestion du monitoring
1. Démon python pour le check des services
Afin de garantir un basculement efficace en cas d’indisponibilité d’un des nœuds du cluster MinIO, nous avons développé un démon python qui va vérifier l’intégrité de l’état des services. Ce daemon est utilisé par nos HAProxy afin de réaliser un check.
A chaque requête de monitoring de notre HAProxy arrivant sur ce démon, celui-ci va ensuite surveiller les 3 services qui dépendent les uns des autres (MinIO, KES, Vault).
Si un seul des trois services devient hors service, les proxy déclarent le nœud complet hors service et basculent 100% du trafic sur le second.
2. Prometheus + grafana
MinIO est développé avec une intégration Prometheus, ce qui permet de collecter les données de manière très régulière. En plus de cela, chacun de nos serveurs liés à l’utilisation de MinIO est surveillé par le biais de l’outil node_exporter.
La création des dashboards grâce à l’utilisation de Grafana permet une accessibilité aux données de manière structurée et personnalisée.
Les deux dashboards fourni par MinIO sont :
- MinIO Dashboard
- MinIO replication Dashboard
Un autre dashboard personnalisé a été créé pour surveiller le tiering des objets du hot vers le warm.
3. Icinga
Icinga est l’un des outils utilisé pour le monitoring au niveau système. Il permet de recevoir des alertes (emails, SMS, chat) en cas de défaillance technique. Nous réalisons le monitoring classique (disques, RAM, CPU, démons, etc …) ainsi que l’état de tous les services liés à l’infrastructure MinIO (MinIO, vault et KES).
9. Conclusion et leçons apprises
Grâce à ce projet, nous avons pu mener à bien notre modernisation vers une véritable gestion standardisée des fichiers.
En effet, grâce à cette redondance des fichiers sur deux datacenters, la force du chiffrement natif de MinIO et tout ce qu’apporte le protocole S3 (comme la gestion de versions), nous avons “LA” solution redondée et sécurisée répondant à nos besoins.
Nous avons appris que malgré des benchmarks importants et la tentative de reproduire ce qu’il se passait en production, nous pouvions passer à côté de certains éléments. Même si nos problèmes de latence n’ont eu que peu d’impact sur la production (seulement un temps de mise à disposition de nos traitements plus long que d’habitude), nous n’avons jamais perdu de données.
Le fait d’avoir sous-estimé le travail du scanner MinIO sur des millions de petits fichiers, nous a aussi permis d’approfondir l’étude de ce scanner et de l’adapter à nos besoins (entre rapidité de celui-ci et utilisation des disques (I/O)).
10. Avenir de MinIO
Fin 2025 MinIO a décidé de “geler” sa version community. Cela était attendu, car depuis 2024 certains signes montraient déjà des changements dans la community edition, comme le changement de licence, la fin des images docker et enfin la fin de l’interface d’administration.
Nous commençons déjà à étudier l’avenir de MinIO au sein de notre infrastructure, mais nous pensons que nous avons encore environ une année devant nous avant de devoir réaliser la migration des données.
Pourquoi un an ? Notre infrastructure MinIO est 100% locale, jamais exposée sur internet, nous pensons donc que nous ne serons pas confrontés à de gros problèmes de sécurité, mais si c’était le cas, nous avons les compétences en interne afin de construire une nouvelle version avec l’ajout de correctifs de sécurité.



